
Test-Workshop eines Prototyps zur Datenschutz-bewussten Exploration von Mobilitätsdatensätzen
freemove lädt die Mobilitätsszene zum fachlichen Austausch an die TSB
Markus Sperl- Privatsphäre-erhaltende Technologien (PETs)
- Privatsphäre
- Prototyp
- Stakeholderintegration
- Mobility as a Service (MaaS)
- Transdisziplinarität
Am Donnerstag, den 19.05.2022, hatte das Projekt freeMove nach einem weiteren Pandemiewinter endlich die Möglichkeit, in Präsenz mit Praxisvertreter:innen in Austausch zu treten. Ausnahmsweise nicht in den Räumlichkeiten des CityLABs, fand sich eine bunt gemischte Gruppe aus der Mobilitätsszene in der Grunewaldstraße unter dem Dach der Technologiestiftung zusammen. Von ÖPNV, MaaS-Unternehmen wie Sharing-Diensten, Ridepooling oder Routing-Anbieter:innen bis Smart-Mobility-Expert:innen fanden sich Vertreter:innen zusammen, um ihre Einschätzungen zu einem im Projekt entwickelten Prototypen abzugeben. Für uns ist die rege Teilnahme weiteres Indiz dafür, dass unsere Themen viele beschäftigen, die an der datengetriebenen Verkehrswende arbeiten und die Vorteile guter Datenlage kennen, dabei aber Privatsphäre als Grundrecht geschützt wissen wollen.
Das Verbundprojekt freemove erkennt die Notwendigkeit der Arbeit mit Mobilitätsdaten zur Entscheidungsfindung, Planung und Anpassung an und erforscht transdisziplinär Möglichkeiten einer datenschutzbewussten Praxis (Sammlung, Verarbeitung & Weitergabe) im Mobilitätsbereich. Menschliche Bewegungsmuster im städtischen Kontext sind zwar en Gros repetitiv, bergen aber, je nach Granularität, große Risiken im Hinblick auf die Privatsphäre, insbesondere für vulnerable Gruppen. Sicherheitsmaßnahmen wie Anonymisierung bieten oft partiellen Schutz und gehen mit teils großen Einbußen der Datenqualität einher. Der Trade-Off zwischen Privatsphäre und Nutzbarkeit der Datensätze nach Schutzmaßnahme ist Kernproblem des Projekts.
Transdisziplinäre Forschung ist auf Interaktion angewiesen
Dank des wertvollen Feedbacks wird der Prototyp nun in einer Überarbeitungsschleife verbessert und anschließend Praktiker:innen Open Source auf GitHub zur Verfügung gestellt. Durch die wichtigen Rückkopplungen aus Kreisen tatsächlich mit Mobilitätsdaten arbeitender Menschen versuchen wir, dem im Projekt angelegten transdisziplinären Ansatz nachzukommen. Forschung bespielt für freeMove nicht nur den akademischen Diskurs aus verschiedenen disziplinären Blickwinkeln, sondern soll gesellschaftlich nutzbare Ergebnisse im Kontext nachhaltiger urbaner Transformation erzeugen.
 Arbeitsphase im Workshop-Verlauf
Arbeitsphase im Workshop-Verlauf
Ein ready-to-use Python-Package als Projektzwischenergebnis
Nach einem kurzen Impulsvortrag von Prof. Florian Tschorsch (TU Berlin) zum Thema Differential Privacy und der Unmöglichkeit hundertprozentiger Datenanonymisierung stellten Alexandra Kapp und Prof. Helena Mihaljević (HTW) das Python-Package vor, mit welchem sich verschiedene Mobilitätsdatensätze automatisiert und unter Privatsphäregarantien untersuchen lassen. Das Package soll Zugriffe auf sensible Rohdaten durch automatisierte Aggregierung reduzieren und Datenschutz zusätzlich durch eine algorithmische „Verrauschung“ einzelner Datenpunkte mittels Differential Privacy garantieren. Die Exploration von Datensätzen jeglicher Art folgt oft ähnlichen, repetitiven Abläufen und geläufige statistische Metriken und Kennzahlen, die schnell Auskunft über Beschaffenheit von Daten geben, lassen sich automatisch über Programmierschritte ausgeben. Um diese repetitive Arbeit zu beschleunigen und gleichzeitig datenschutz-bewusst zu agieren, lassen sich mithilfe unseres standardisierten Mobilitätsdatenreports Berichte erstellen. Privatsphäre wird gewährleistet, indem Nutzende im Vorfeld bemessen, wie groß das Daten verfremdende, statistische Rauschen sein soll, welches über die Aggregationen gelegt wird. Die Outputs stellen dann wiederum diese statistische Unsicherheit visuell dar und ermöglichen eine Privatsphäre-garantierende Art und Weise, Daten schnell zu sichten und an Dritte weiterzugeben.
Auf die Frage nach bereits bestehenden Lösungen für solche Datenexplorationen, wird häufig auf Unternehmen verwiesen, die kommerziell Daten erwerben und sie visuell aufbereiten.
Die sehr unterschiedlichen Backgrounds der Gäste gingen mit sehr verschiedenen Verwendungsszenarien einher, und damit unterschiedlichen Anpassungswünschen (Flexibilisierung, Visualisierungen), aus denen die Forscher:innen nun die nächsten Schritte selektieren.
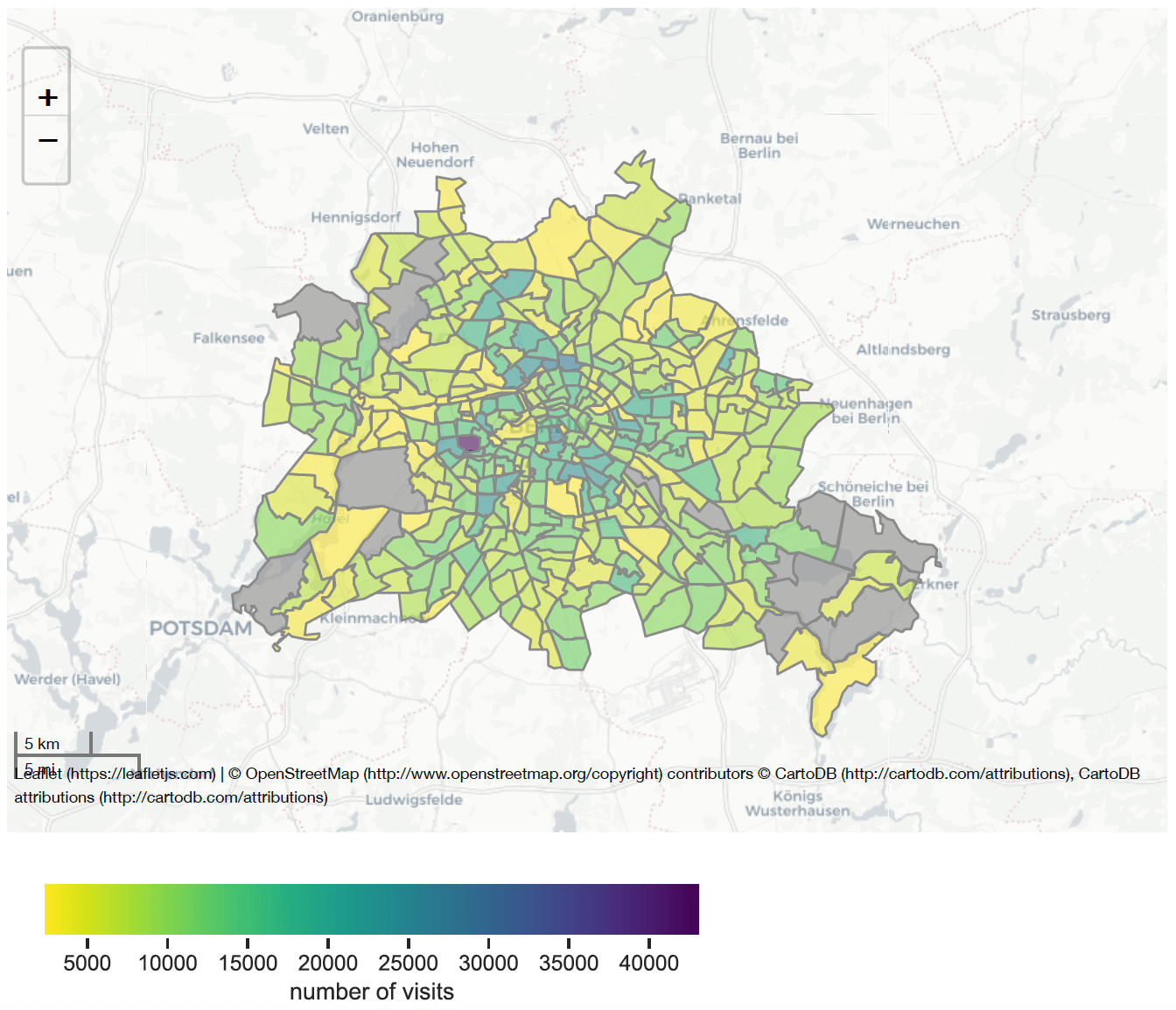 Datenvisualisierung im Mobilitätsdatenreport (fiktive Daten)
Datenvisualisierung im Mobilitätsdatenreport (fiktive Daten)
Wie viel Privatsphäre in welchem Kontext garantiert werden muss, ist gesellschaftlich auszuhandeln
An den Diskussionen lässt sich eine breitere, gesellschaftliche Debatte ablesen, die freemove mit den Stakeholdern führen möchte. Wieviel Privacy ist nötig, und wie verhält sich das zu den von Datenverarbeiter:innen oder -sammler:innen angegebenen Zwecken? Florian Tschorschs anschaulicher Ausschluss perfekter Anonymisierung legt insgesamt einen Hang zur Datenminimierung und Minimierung von Datenzugriffen per se nahe, zugunsten der Privatsphäre, im Kontrast zur geläufigen Praxis der massenhaften Sammlung und Speicherung um Muster zu generieren. Wie in vergangenen Austauschformaten ist für freemove ein Learning, Stakeholder dahingehend aufzuklären Privacy in jedem Stadium der Entwicklung als Standard mitzudenken: Fragestellungen schärfen, um keine unnötige Datenmasse zu generieren, Erhebungsinstrumente so gestalten, dass wenig personenbezogene Daten entstehen, die entstandenen Daten durch privatsphäre-erhaltende Maßnahmen stärken.
Nach einem weiteren Input durch Prof. von Grafenstein zur von freemove geplanten Zertifizierung von Anonymisierungstechnologien wurde der Vormittag beim sonnigen Lunch und Austausch auf der Terrasse der Technologiestiftung abgerundet.
Das freemove-Team der Technologiestiftung bedankt sich bedankt sich bei den zahlreichen Gästen, und den Partner:innen Alexandra Kapp und Prof. Helena Mihaljević (HTW), Dr. Daniel Franzen (FU Berlin), Prof. Florian Tschorsch (TU Berlin) und Prof. Max von Grafenstein (UdK).