
Privacy-preserving Techniques and how they apply to Mobility Data
Alexandra Kapp (HTW)What does it actually mean to “anonymize” data? With this blog post, I want to give an overview of different established methods and how they apply to mobility data. (The survey of Fiore et al., 2020 has been a major source for this overview).
First of all, it should be noted, that there is a difference between privacy principles (abstract definitions), privacy criteria (exact requirements), and mechanisms. For example, the privacy principle ‘indistinguishability’ demands that each record in a database must not be distinguishable from a large enough group of other records. This principle is met by the privacy criterion of k-anonymity which requires that each person in a dataset cannot be distinguished from k-1 other individuals. This, in turn, could be achieved by applying the mechanism of suppression, where each record with a unique combination of identifying attributes (e.g., age, sex, and place of residence) is removed from the dataset.
Let us first have a look at different mechanisms and then at privacy principles and criteria. For demonstration, we use the below example dataset (see Figure 1):
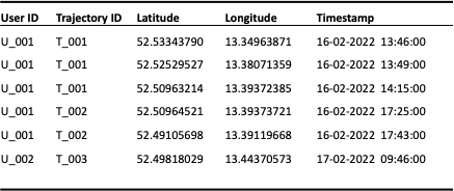 Figure 1: Example mobility dataset
Figure 1: Example mobility dataset
Privacy mechanisms
Mobility data is somewhat special compared to other tabular data for various reasons: while other datasets often only hold a single record for a user, mobility data has potentially many closely linked records of a single user (spatio-temporal points) within a trajectory which makes it harder to anonymize. Additionally, geospatial records cannot (always) be treated as regular numeric values. And last, fine-granular spatio-temporal points are often unique within a dataset, unlike, e.g., a choice from a category like ‘gender’ where multiple users share the same value.
In the following part, we will have a look at the mechanisms of cloaking, suppression, aggregation, obfuscation, swapping, and synthetic data generation and how they apply specifically to mobility data.
Cloaking (Generalization)
The level of detail can be reduced to improve anonymity, which is also referred to as generalization. This is often achieved by creating categories, e.g., a dataset of customers including demographic information can be generalized by replacing the exact age with 5-year categories (15 < age ≤ 20, 20 < age ≤ 25, etc.).
Mobility data can be generalized by reducing the spatial or temporal granularity, also referred to as cloaking. The spatial accuracy can be reduced by truncating latitude and longitude decimals (see Figure 2) or by mapping points onto a tessellation (see Figure 3) and replacing coordinates with tile IDs.
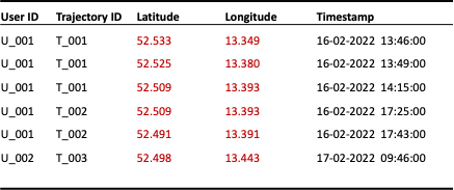 Figure 2: Reduction of spatial granularity by truncation of latitude and longitude to three decimals
Figure 2: Reduction of spatial granularity by truncation of latitude and longitude to three decimals
 Figure 3: Reduction of spatial granularity by mapping coordinates onto a tessellation
Figure 3: Reduction of spatial granularity by mapping coordinates onto a tessellation
Another option is the reduction of temporal accuracy by discarding every other point within a trajectory (see Figure 4) or by binning exact timestamps into pre-defined time windows (see Figure 5).
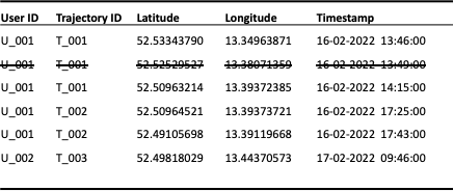 Figure 4: Reduction of temporal granularity by reducing the sample interval to a minimum of 10 minutes
Figure 4: Reduction of temporal granularity by reducing the sample interval to a minimum of 10 minutes
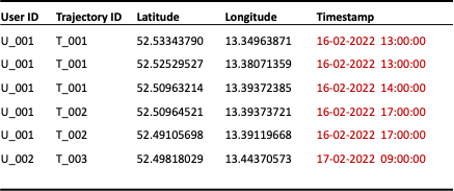 Figure 5: Reduction of temporal granularity to the hour
Figure 5: Reduction of temporal granularity to the hour
Simple applications of cloaking techniques did not provide great protection against attacks, as shown in various research (see Fiore et al., 2020).
Suppression
Another straightforward privacy mechanism is suppression. Entire columns or single sensitive values are thereby removed from the dataset. For example, columns containing the bank account number of users could be entirely discarded.
In the context of mobility data, sensitive locations could be suppressed. For example, all records within a 50-meter radius of hospitals could be removed from the dataset to protect the privacy of patients (see Figure 6).
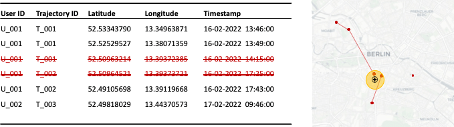 Figure 6: Suppression of records close to sensitive locations (e.g., a hospital)
Figure 6: Suppression of records close to sensitive locations (e.g., a hospital)
However, sensitive locations that allow easy re-identification are usually user-specific (like home or workplaces). Suppression of such locations thus relies on user-specific information, e.g., the fitness trackers Garmin or Strava allow the declaration of “privacy zones” where all activities within the zones are snapped to the zone perimeter when shared publically.
As a heuristic, it can be assumed that the most sensitive locations usually reside within the origin and destination of a trip and not within the path in-between. Thus, another suppression approach lies in truncating the first and last meters of a trajectory (presuming fine-granular data, e.g., a GPS trajectory). Of course, this is only a suitable technique if the start and end locations are not of interest.
Aggregation
Mobility data is commonly aggregated spatially, temporally, or a combination of both. Aggregation functions thereby do not only serve analysis purposes but can also be used to provide privacy (see Figure 7).
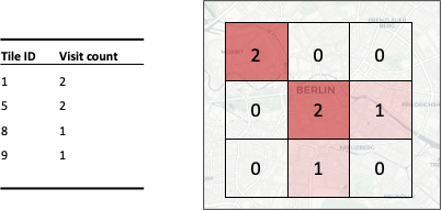 Figure 7: Spatial aggregation of tile visits
Figure 7: Spatial aggregation of tile visits
Simple spatial aggregations treat single points of a trajectory individually, without maintaining information on the relation of points within a trajectory. To retain such information, more fine-granular aggregations need to be performed, commonly by origin-destination matrices or by aggregating trip counts per road segment (i.e., traffic volume).
These examples already indicate that aggregations of mobility data often remain at a fine-granular level which, by itself, is likely not providing enough privacy (e.g., Xu et al., 2017 or Pyrgelis et al., 2017).
From a utility perspective, aggregation only makes sense if the desired information is known in advance. Once data is aggregated and raw data is discarded, further analyses might not be available anymore. E.g., if data is aggregated spatially it cannot be disaggregated temporally anymore if the underlying raw data was deleted.
Obfuscation (Noise)
Numerical values can be distorted by adding noise. An age of 24 might then be changed to 26 after applying a noise function (value distortion technique, see Agrawal and Srikant, 2000).
In the context of mobility data, noise can be added to coordinates, distorting them from their original location. Obviously, this results in unrealistic trajectories with zigzag shapes (see Figure 8). Smarter approaches including smoothing techniques have been proposed in the context of ship trajectories by Jiang et al. (2013) and Shao et al. (2013).
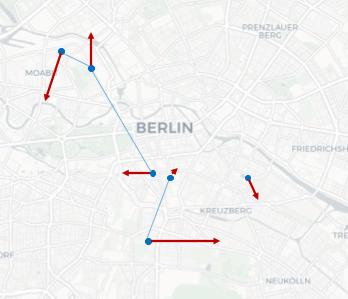 Figure 8: Spatial distortion by adding noise to coordinates
Figure 8: Spatial distortion by adding noise to coordinates
Duckham and Kulik (2005) formalized a model of obfuscation for location data that does not distort single coordinates; instead, a set of potential locations is provided, including the actual location, though not revealing which one is the true location (see Figure 9). Their model is directed at location-based service apps that query single locations of a user to provide a service (e.g., to return a recommendation for the closest Italian restaurant). The true closest restaurant should still be returned correctly, even when only the imprecise information of a set of potential locations is known.
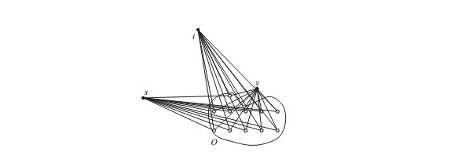 Figure 9: Model of obfuscation by Duckham and Kulik (2005): Given a setting, where the closest restaurant to the user shall be identified, where s, i, and y are the restaurant candidates. Obfuscation set O (containing the true location of the user) is provided to the location-based service application which can identify restaurant y as the closest one without knowing the actual true user location. Figure from Duckham and Kulik (2005)
Figure 9: Model of obfuscation by Duckham and Kulik (2005): Given a setting, where the closest restaurant to the user shall be identified, where s, i, and y are the restaurant candidates. Obfuscation set O (containing the true location of the user) is provided to the location-based service application which can identify restaurant y as the closest one without knowing the actual true user location. Figure from Duckham and Kulik (2005)
Swapping
Swapping is an anonymization mechanism where values of a dataset are rearranged so that attributes remain present but do not correspond with their original records (see Figure 10).
For mobility data, this can be applied by swapping trajectory segments where trajectories are close to one another, for example with the technique SwapMob, proposed by Salas et al. (2018).
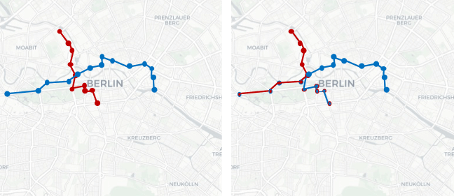 Figure 10: Swapping of trajectory segments. Left: original trajectories of person 1 (red) and person 2 (blue). Right: swapped segments (outline color indicates original
Figure 10: Swapping of trajectory segments. Left: original trajectories of person 1 (red) and person 2 (blue). Right: swapped segments (outline color indicates original
The utility of such approaches is limited for use cases where origin-destination combinations or the course of the trajectory are relevant.
Synthetic data generation
Data synthetization techniques have a different approach than the previous mechanisms that aim to alter attributes of raw data. Certain distributions of the raw data are captured instead (e.g., distribution of origin-destination pairs, distribution of trip lengths, temporal distribution of trips, etc.) and new, synthetic data is created based on the learned distributions. There are different approaches to go about this, e.g., WHERE (Isaacman et al., 2012) defines five input probability distributions that are used to create synthetic data, DP-Star (Gursoy et al., 2019) uses trip distribution information and creates micro-trajectory data based on Markov chains, while other approaches are based on neural networks that are trained to learn sequences without necessarily specifying which distributions should be captured (e.g., Rao et al., 2020, Berke et al., 2022).
Combination of mechanisms
Mechanisms can also be combined. For example, noise can be added to spatially aggregated tile visit counts, or information on tile visits is suppressed if the count is below a certain threshold.
Privacy principles and criteria
Mechanisms can be applied as privacy enhancements without fulfilling a privacy criterion. Though, this makes it difficult to impossible to quantify privacy risks and make statements on privacy guarantees. For example, the reduction of granularity by rounding coordinates to three decimals could provide enough privacy in a dense city but maybe not for the sparsely populated countryside. Maybe travel patterns between cities are sensitive information, thus coarsening on city-level would still reveal unique travel patterns of individuals.
Privacy criteria define requirements that need to be met, thereby allowing a better assessment of the provided privacy. Privacy criteria can be classified according to the privacy principle (an abstract definition of privacy) they fulfill.
Two major privacy principles have been considered in the literature: indistinguishability and uninformativeness.
Indistinguishability & k-anonymity
Indistinguishability demands that each record in a database must not be distinguishable from a large enough group of other records. This is usually implemented via the privacy criterion k-anonymity (see Figure 11).
“A release provides k-anonymity protection if the information for each person contained in the release cannot be distinguished from at least k-1 individuals whose information also appears in the release” (Sweeney, 2002).
K-anonymity is mostly achieved with generalization and suppression.
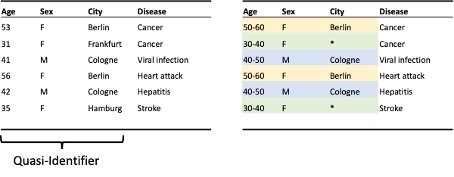 Figure 11: Example of k-anonymity. Left: raw data. Right: Anonymized data providing k-anonymity where k=2 (same color indicates common groups). Anonymization is reached by generalizing age and suppression of unique cities
Figure 11: Example of k-anonymity. Left: raw data. Right: Anonymized data providing k-anonymity where k=2 (same color indicates common groups). Anonymization is reached by generalizing age and suppression of unique cities
To provide k-anonymity for mobility data, it must be ensured that any trajectory appears at least k times within the dataset. This is usually achieved by mapping coordinates onto a tessellation (spatial generalization) and/or suppressing unique (segments of) trajectories. This is not trivial as trajectories tend to be rather unique and often only very coarse tessellations and time windows can attain even 2-anonymity, thus coming at a high cost of spatiotemporal accuracy (Figure 12).
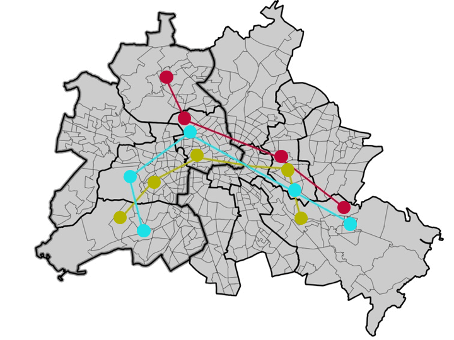 Figure 12: In this example, there are three potential zonings. Only the coarsest zoning of east and west would provide 2-anonymity.
Figure 12: In this example, there are three potential zonings. Only the coarsest zoning of east and west would provide 2-anonymity.
Of course, this also depends on the characteristics of the data. Generally speaking, the longer and more fine-granular trajectories are, the harder it becomes to provide k-anonymity.
To maintain a higher utility, there are approaches that only view the first and last bit of a trajectory as sensitive information, thus only providing k-anonymity for those parts (Xu et al., 2021).
L-diversity and t-closeness build on the concept of k-anonymity by defining further restrictions on sensitive attributes that are allowed to be present within a group. E.g., if all people within a group have been to a hospital, an attacker does not need to know which exact person within this group his target is to know that his target has been to a hospital. With l-diversity and t-closeness criteria requirements of such differences within sensitive attributes can be formulated.
Uninformativeness & differential privacy
Uninformativeness is a very general principle, enforcing that the difference between the knowledge of the adversary before and after accessing a database must be small. Unlike indistinguishability, it does not make any assumptions on prior knowledge of an attacker and therefore provides much stronger privacy guarantees. Uninformativeness is mostly implemented via differential privacy, which has become the de-facto standard of privacy guarantees (Dwork et al., 2006).
“An algorithm is said to be differentially private if by looking at the output, one cannot tell whether any individual’s data was included in the original dataset or not. In other words, the guarantee of a differentially private algorithm is that its behavior hardly changes when a single individual joins or leaves the dataset — anything the algorithm might output on a database containing some individual’s information is almost as likely to have come from a database without that individual’s information” (Harvard University Privacy Tools Project).
(See this blog post for a more in-depth explanation of differential privacy)
Differential privacy is especially applied in settings of database queries (unlike a data release) by applying noise to the output, e.g., spatially aggregating data and applying noise to each visit count of each zone. The noise is thereby calibrated accordingly (determined by the so-called sensitivity) so that the output guarantees differential privacy according to a defined privacy budget (determined by the parameter ε). For mobility data, differential privacy mechanisms can be applied to any kind of aggregations, just as they would be applied to aggregations of any other tabular datasets.
For the setting of location-based service applications, the concept of geo-indistinguishability (Andrés et al., 2013) has been established to provide differential privacy for single locations (unlike trajectories) within a defined radius.
Haydari et al., 2021 make use of the concept of geo-indistinguishability to provide differential privacy for origin and destination locations (the trip inbetween is not considered sensitive information) for the publication of aggregated mobility network data which informs about travel demand on street segments, e.g., for congestion analysis.
For the release of entire trajectories, there is increasing research on differentially private synthetic data generation, e.g., Mir et al. (2013), He at al. (2015), Gursoy et al. (2018), or Chen et al. (2020).
Conclusion
The given overview hopefully provides insights into potential privacy mechanisms and criteria. As anonymization techniques are dependent on the context, such as data characteristics, use cases, and privacy threats, there is no one method that fits as a solution to all situations.
Dieser Text erschien zuerst auf Alexandras privatem Blog.